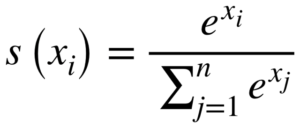ソフトマックス関数(ソフトマックスかんすう、英: softmax function)や正規化指数関数(せいきかしすうかんすう、英: normalized exponential function)は、シグモイド関数を多次元に拡張した関数。多クラス分類問題において、ニューラルネットワークの出力を確率分布に変換することができるので、最後の活性化関数としてよく用いられる。
ソフトマックス関数という呼び名は人工知能の分野での呼び方であり、関数自体は1868年にルートヴィッヒ・ボルツマンが発表した統計力学のボルツマン分布に由来する。交差エントロピーとの組合せでよく用いられるが、ボルツマン分布とエントロピーの組合せの考え方も統計力学由来である。ボルツマンマシンでも用いられているが、1989年にJohn S. Bridleがsoftmaxと命名した。
定義
ソフトマックス関数は、K 個の実数からなるベクトル を入力として受け取り、入力の指数に比例する K 個の確率で構成される確率分布に正規化する。つまり、ソフトマックス関数を適用することで、各成分は区間 (0, 1) に収まり、全ての成分の和が 1 になるため、「確率」として解釈できるようになる。入力値が大きいほど「確率」も大きい。
に対し、標準(単位)ソフトマックス関数 は次のように定義される。
簡単に言えば、入力ベクトルの の各成分 に自然指数関数を適用し、これらすべての指数の合計で割ることによって、値を正規化する。この正規化により、出力ベクトル の成分の和が 1 になることが保障される。
シグモイド関数との関係性
K = 2 の二値分類問題において、 と置くと、標準シグモイド関数になる。z の正負で二値分類できる。
基底がネイピア数以外の場合
e(ネイピア数)の代わりに別の基底 b > 0 を用いることもできる。 0 < b < 1 であれば、入力値が小さいほど出力される確率が高くなり、b の値を小さくすると、入力値が小さいところに集中する確率分布となる。b > 1 の場合、入力値が大きいほど出力される確率が大きくなり、b の値を大きくすると、最大の入力値が大きい位置に集中する確率分布が作成される。
実数 β を用いて ないし と記載すると、次の表現を得る。
基底が固定されている分野もあれば、基底を変化させる分野もある。ニューラルネットワークの場合は、ソフトマックス関数を適用する前に線形変換することが多く、その場合はこの β 倍は無意味である。
偏微分
偏微分は、クロネッカーのデルタを使用し、商の微分法則より下記となる。
交差エントロピーと組み合わせた場合
教師データ が0または1の多クラス分類問題で、 で、損失関数に交差エントロピーを使用した場合、
に対して、正解がj、つまり とすると、
となり、これを で偏微分すると になる。つまり、ソフトマックス関数適用後の確率分布に正解の所だけ1を引いたものになる。
トップダウン型自動微分を使用する際は、この値をソースノードに降ろしていけば良い。
ちなみに、回帰問題で二乗和誤差 を で偏微分すると と、上記と似たような式になる。つまり、バックプロパゲーションとしては、回帰問題で二乗和誤差の場合は出力の誤差を使用し、分類問題でソフトマックス関数で交差エントロピーの場合は確率の誤差を使用する。
オーバーフロー対策
の値が大きい場合、単精度浮動小数点数の場合は であっても、exp() の計算後の結果がオーバーフローして無限大になる。そして、無限大÷無限大は NaN になる。その対策として、 は一律同じ値を引いてもソフトマックス関数を適用後の結果は変わらないことを利用して、 として計算すると良い。
解釈
Arg max の滑らかな近似
「ソフトマックス softmax」という名前は誤解を招く恐れがある。この関数は最大値関数の滑らかな近似ではなく、Arg max関数(どのインデックスが最大値を持つかを表す関数)の滑らかな近似値である。実際、「softmax」という用語は、最大値の滑らかな近似である LogSumExp関数にも用いられる。これを明確にするために「softargmax」を好む人もいるが、機械学習では「softmax」という用語が一般的である。
関連項目
- 多項ロジット回帰
- ディリクレ分布 – カテゴリ分布をサンプリングする別の方法
- 分配関数
脚注
出典
外部リンク